This is a question that I regularly ask those attending my high availability and disaster recovery presentations: is your SQL Server Always On Availability Group really highly available?
Now, don’t get me wrong. I love the Always On Availability Groups feature in SQL Server (except for the price tag of an Enterprise Edition license.) But there’s a back story why I ask this question. Back in 2013, one of my customers asked me to build an Always On Availability Group infrastructure for their SharePoint 2013 farm. Back then, there was a lot of talk and promotion in the SharePoint community about using the new *cough* Always On *cough* feature in SQL Server 2012. Almost everyone I met at conferences who were planning on upgrading their SharePoint 2010 farms to SharePoint 2013 were looking at implementing Always On Availability Groups.
Fast forward to go-live and a happy customer. Their farm is running on SharePoint 2013 with SQL Server 2012 Always On Availability Groups on a 2-node Windows Server 2012 cluster. They used a file share witness for the extra vote on their cluster since they were only using standalone instances for the Always On Availability Group replicas. The file share witness went offline for whatever reason. But since the cluster nodes are still available, the Always On Availability Group remains online together with the SharePoint databases in it. Until somebody rebooted the secondary replica due to installation of security patches. That caused the SharePoint farm to go offline because the Always On Availability Group went offline. One of my colleagues back then was telling me that we are getting blamed for what happened to their SharePoint farm. I told them, “that behavior is by design.”
It’s easy to fall into the belief that something works until it doesn’t. And, then we blame someone – either the vendor or the one who implemented the solution – when it doesn’t. That’s why we need to understand the underlying infrastructure and it’s behavior.
Since SQL Server Always On Availability Groups (AGs) (as well as failover clustered instances (FCIs)) depend so much on the underlying Windows Server Failover Cluster (WSFC) for health detection, automatic failover, etc., we need to understand how WSFC works and how it actually keeps the applications running on top of it online.
Why Quorum Matters
As per this TechNet article, the quorum for a cluster is determined by the number of voting elements that must be part of active cluster membership for that cluster to start properly or continue running. This means that the number of voting members in a WSFC determine whether or not the cluster stays online together with the applications running on top of it. You’ll commonly see a 2-node WSFC – both for AG and FCI – because of simplicity and ease of management. A disk witness (commonly known in the past as a disk quorum) is typically used for an FCI while a file share witness for AGs with standalone instances as replicas.
Every node in the cluster, by default, will have a vote. In order to keep the cluster up and running, the total number of votes have to reach a majority. The calculation for majority of votes is as follows:
Majority = (Total Number of Votes from Voting Members / 2) + 1
I mentioned voting members because there are a dozen or more combinations of configuration that you can implement where the voting members may or may not have a vote, depending on your requirement. This could mean having a node that does not have a vote if you’re on earlier versions of Windows Server. But, first, let’s start with the common 2-node cluster and how quorum behaves on different versions of Windows Server.
In a 2-node cluster, the majority of votes will be one (1.) And because both nodes in a cluster will have a vote, by default, we don’t really have a majority since 50% is sitting right in the middle. This is the reason why an additional vote in the form of a disk or file share witness is introduced. We need a “tie-breaker” in order to have majority of votes. Now that we have three (3) votes – two from the cluster nodes and one from the witness – the majority of votes will be two (2) – three divided by two is 1.5, plus one is 2.5 (I’ve never really gotten the hang of doing math using words in a sentence.) We need to round down the results of the calculation of votes since we cannot really have half-a-vote. 66.67% is definitely higher than 50%, making it a majority. You can use this same logic to calculate the majority of votes for any number of nodes in your WSFC to keep it online and available.
So, Is My Always On Availability Group Really Highly Available?
Since our goal is to keep the WSFC online, we have to make sure that majority (if not all) of the voting members remain online and available. Just because a voting member is online doesn’t mean it is available from the WSFC’s point of view. It could mean that the network switch that connects one of the nodes to the WSFC become unavailable, causing it to be disconnected and not communicate with the other nodes. The node is online but it isn’t available as far as the WSFC is concerned.
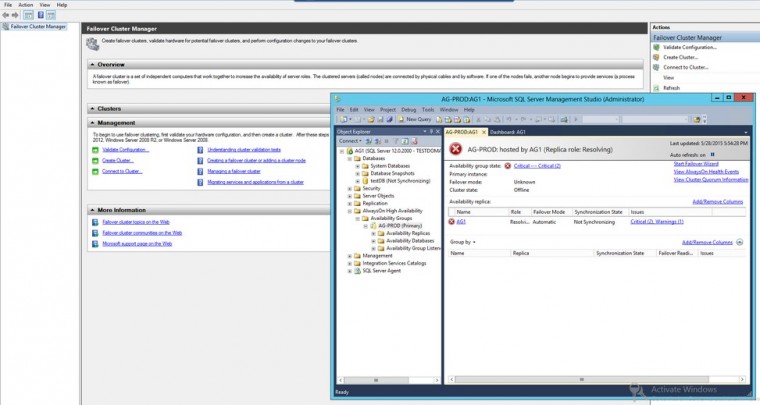
So, with Windows Server 2012 (same as with Windows Server 2008/R2,) when I lost the file share witness, I still have two out of three votes (majority of votes) that kept the WSFC online. When somebody rebooted the secondary replica because of the installed security patches, the WSFC only had one out of three votes which is less than majority of votes. Doing so took the WSFC offline which also took the Always On Availability Group offline. Below is a screenshot of an SQL Server 2014 AG configuration that runs on Windows Server 2012 where the network connectivity between the nodes in the WSFC became unavailable.
Note that while the SQL Server instance is still online because it’s a standalone instance, the AG and the databases in it are offline and inaccessible. This means you can still connect to the SQL Server instance, run some queries against DMVs or the system databases but the AG databases are offline. And because the AG contained the SharePoint databases, the SharePoint farm went offline.
Introducing Dynamic Quorum
The customer panicked and complained when that happened. For one, they expected the AG to stay online regardless. Unfortunately, they were not monitoring the file share witness and, while it remained offline, somebody rebooted the secondary replica. This would not have happened if the file share witness remained online while the secondary replica was rebooted.
The good thing is that they were on Windows Server 2012. This version of Windows Server introduced the concept of dynamic quorum and is enabled, by default. The WSFC manages the vote assignments to the nodes depending on their state. If the node is taken offline – rebooted, powered down, disconnected from the network, etc. – it’s vote is also removed from the cluster. It’s the reason why the AG went offline when the cluster node was rebooted. The beauty of this is that, when the node came back online, the cluster went back online (together with the AG) by virtue of the vote being added back to the WSFC. This was worse in earlier versions of Windows Server in that, if the WSFC went offline, the only way to bring it back online was to force start without quorum. Unfortunately, even when the WSFC came back online eventually, the SharePoint farm still was taken offline and was down for almost half an hour because it took a while to reboot the server.
And Dynamic Witness
Windows Server 2012 R2 introduced the dynamic witness feature. From the name itself, the WSFC dynamically adjusts the voting capability of the witness resource based on the number of votes required to meet quorum. This works in tandem with the dynamic quorum feature in Windows Server 2012 to enable the WSFC to maintain availability when any of the voting members become unavailable which also eliminates the additional administrative overhead of having to keep an odd number of votes.
Know Where You Stand
With AGs dependency on WSFC, there’s a lot that we DBAs need to be aware of that go outside the scope of their traditional job description. We need to know about Active Directory, DNS, networking, WSFC and AGs just to keep our databases highly available. So, in order to really know if your AGs are highly available,
- 1. Monitor your cluster. This means the nodes, the witness and everything in it. You need to be alerted when the number of voting members fall below total but still higher than majority. That way you can decide early on how to deal with it.
- 2. Know what version of Windows Server you’re running. Different versions of Windows Server behave differently when it comes to the quorum. I’ve described how Windows Server 2012 behaves. Windows Server 2012 R2 introduced the concept of dynamic witness where the witness vote is dynamically adjusted based on the number of voting nodes in the WSFC. I’ll save the details of dynamic witness in a future blog post but knowing what version of Windows Server you’re running will give you an understanding of what to expect.
- 3. Identify steps should any of the voting members in your WSFC fail. If any of the voting members in the WSFC become unavailable, know what steps you need to take. If the file share or disk witness went offline, maybe an alternative file share can be configured temporarily. This can be automated via a PowerShell script.
- 4. Document your configuration and recovery steps. Once you’ve identified how you can address issues when they happen, include them in your documentation. This will help your junior DBAs or operations engineers to resolves issues in case you decide to go on vacation.
There really is no guarantee that your AGs will always be highly available all of the time. That’s why it’s important to define your recovery objectives and service level agreements. But knowing where you stand and how you can resolve issues when they occur can help you meet your availability goals.
Additional Resources
- Understanding Quorum in a Failover Cluster
- What’s New in Failover Clustering in Windows Server
- Getting Started with AlwaysOn Always On Availability Groups (SQL Server)
Schedule a Call


Hi Edwin,
First of all I´d like to congratulate you… great article, with rich content.
I think lots of environments (many I´ve been to) unfortunately are not high availble although there might be high availability solutions deployed to those environment.
Again, unfortunately, many professionals don’t care about learning a little bit out of box… that´s is the cause of many issue in the environment where they are sys admins.
So, in those case (and most of them), I think the technology (AlwaysOn AG & AlwaysON FCI) if well implemented and monitored, are reliable and the sys admins of those environment can surely state “My SQL Server Availability Group is HIGH AVAILABLE”
Once again, congratulations,
sincerely,
Edvaldo Castro
PS.: I love High Availability and Disaster Recovery;
Hi Edvaldo,
Agreed, it takes a well designed, well managed system for it to be really highly available. And that requires a lot of attention and intent (there’s a reason my blog has the tag line “Intentional Excellence”) because excellence does not happen without intent.
Thanks for your comment.
Hi,
This was such a nice article that will enrich the knowledge of anyone. Thanks for sharing.
Now, I have one query and problem that I faced recently.
I have implemented Skype for business in my environement. And for this, we need to deploy 2 Backend database servers. We have implemented SQL 2014. There are 2 nodes and I have configured Always ON High Availability between these 2 nodes. One is Primary and Second is Secondary.
Now, I want to implement SQL 2014 SP2 on it. So as a standard practice, we need to do failover from Primary to secondary node. Then apply SP2 and reboot primary. Then failback to Primary.
But, when I do manual failover, the secondary node gets rebooted automatically.
I cannot understand why this is happening and what can be done for resolution.
Any valuable help appreciated.
To apply patches and services packs on an Availability Group configuration, always start with the secondary/standby. Before you do so, you need to remove the cluster node from the Possible Owners list from within the Failover Cluster Manager. That way it does not affect the primary should you have any issues during the patching process. Once the secondary/standby is patched, reboot the machine if necessary, add it back to the Possible Owners list and failover the Availability Group to this patched server. Then, repeat the process for the other server. This minimizes the amount of downtime incurred as a result of the failover process.
I’m not really sure what caused the secondary node to automatically reboot. Could it be that there are other processes running on the secondary that caused it to reboot? Like Windows updates that get automatically applied and server rebooted?
Great article.
Have more then 10 years of experience with Microsoft clustering.
Although it’s not so sexy to say it I am not sure that the Microsoft clustering environment will give you better availability then standalone server. There are so many components that can fail (storage, storage networking, witness, servers, virtual environment affinity rules and so on…) while in a standalone environment you have only the server itself.
I totally agree. I love the technology but requirements come first when it comes to providing solutions. If a standalone environment is more than enough to meet recovery objectives and service level agreements while making sure that it is cost effective and manageable (meaning the staff is capable enough to maintain and support it), I’m all for it.