
You’re on the phone to get a technical issue resolved. You checked the service provider website and noticed that their phone support is available 24/7. You dial the direct number, expecting a quick response. Ah, the sound of a live phone operator – not a system generated voice prompt – in less than a minute. Within a few minutes, the phone operator decides to escalate the issue to a more senior engineer. “Now, that doesn’t happen often“, you think. Your call was forwarded for escalation and the next thing you know, you’ve been waiting on the phone for 45 minutes.
Does that sound familiar?
Businesses who rely on Amazon Web Services have been impacted by the recent Amazon outage. I, for one, scrambled to test accessing my video files when I found out about the incident. My online course video files are stored on Amazon S3, particularly on the US-EAST-1 region. The good thing is that my online course wasn’t affected by the outage. But I did send an email update to my course subscribers regarding the potential impacts of the Amazon outage.
Did you read the fine print?
Read thru my blog archive and you will notice a common theme when it comes to high availability and disaster recovery (HA/DR). I’m a big fan of processes. In fact, whenever I get called in to do a HA/DR project, I always start off with what I refer to as the “Alphabet Soup of HA/DR” followed by explaining the importance of “The Lion, The Switch and the Wardrobe.”
Designing & implementing HA/DR solutions should be focused more on the process & people aspect. Share on X
The more dependencies you have, the more you need to focus on the people and process aspect of your design. Especially when you are considering moving some of your workloads to the public cloud. Here’s what I mean.
I’ve taken screenshots of the virtual machine service level agreements (SLA) – both for Amazon and Microsoft Azure – and highlighted what we technical professionals usually tend to focus on.

Amazon EC2 SLA
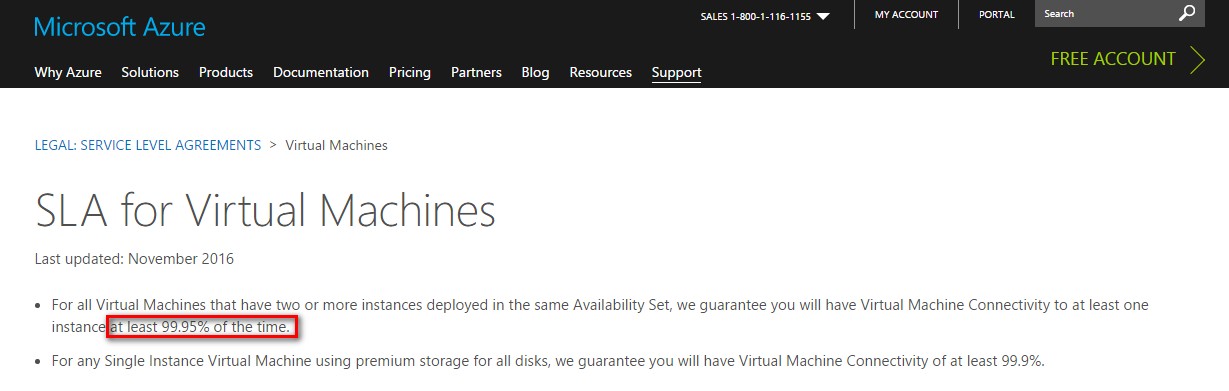
Microsoft Azure VM SLA
Microsoft has also introduced an improved SLA for single-instance virtual machines. I highlighted virtual machines and not the database-as-a-service platform – Amazon RDS and Azure SQL Database – because VMs are the shortest path towards your journey to the public cloud.
But what you might end up missing is the fact that meeting the 99.95% SLA, for Microsoft Azure VMs, you need to have
- – at least two or more VM instances
- – the VM instances should be deployed in the same Availability Set (I’ll cover the concepts behind Availability Sets in a future blog post)
- – only the VM instances are protected, not the workloads inside the VMs
The same principles apply to Amazon EC2 VMs. In fact, they apply to any Infrastructure-as-a-Service (IaaS) platform, regardless of the service provider. For now. Until we see additional enhancements in virtualization platforms.
What the cloud providers say…
In an ideal world, a 99.95% uptime means a potential service downtime/unavailability of
- – Daily: 43.2 seconds
- – Weekly: 5 minutes and 2.4 seconds
- – Monthly: 21 minutes and 54.9 seconds
- – Yearly: 4 hours, 22 minutes and 58.5 seconds
Source: Uptime.is
But didn’t I just highlight the prerequisites in order to satisfy this SLA? It means
- -having at least two or more VMs; translating to increased acquisition and operations cost
- -having the VMs deployed in an Availability Set; requiring an understanding of what Availability Sets are and knowing how to configure them resulting in increased complexity
- -having a high availability solution for the workloads running inside the VM; again, additional complexity and cost
Whoever said moving to the cloud was cost-effective was not considering the economics of managing the right expectations.
Managing The Right Expectations
Ask yourself the following questions as you are in the process of designing hybrid SQL Server HA/DR solutions:
- – How critical is this database to the overall business operations?
- – What’s the agreed upon RPO/RTO/SLA as defined by the business stakeholders – both for HA and DR?
- – What’s the working budget to get this solution implemented?
Based on your responses to these questions, you can then proceed to identify the right solution and the right cloud provider. For example, in a hybrid HA/DR solution, you would be more concerned about local high availability RP/RTO/SLA. Would you need more than one VM on the cloud for your SQL Server databases to meet your DR requirements? Probably not. Unless you require more than 99.95% uptime – even for DR.
Additional Resources
- Why People and Processes Matter More Than Technology
- Disaster Recovery is More Than Just Technology Part 2: The Alphabet Soup
- Disaster Recovery Is More Than Just Technology Part 3: The Lion, The Switch and The Wardrobe
- The Unrealistic HA/DR Belief That Is Costing You A Lot Of Money
- Recent Amazon and Skype Outages and The Cost Of NOT Having A Proper HA/DR Strategy
Schedule a Call

