I previously wrote about Data Types and How They Affect Database Performance which was a way to get database developers to think about the small things that affect overall performance. As a high availability and disaster recovery (HA/DR) professional myself, I like to think of how data types affect database availability and recoverability. The fact is, all SQL Server HA/DR features are affected by the amount of transaction log records generated both by user and system transactions.
Transaction log records are read during a database’s recovery process. Whenever the SQL Server service is restarted, the transaction log file is read as part of the recovery phase, committed transactions are persisted to the data file (REDO phase) and uncommitted transactions are rolled back (UNDO phase) to keep the database in a transactionally consistent state. A more comprehensive discussion of the recovery phase is described in the Understanding How Restore and Recovery of Backups Work in SQL Server topic in Books Online. Every SQL Server HA/DR feature runs either just the UNDO phase or the whole recovery process.
- – Backup/restore. After the data copy phase completes as part of restoring a backup, the recovery process kicks in.
- – Failover clustering. Failover is basically the process of intentionally (manual) or accidentally (automatic) stopping the SQL Server service from the current active node to any one of the nodes in a failover cluster.
- – Database mirroring/Availability Group. The transaction log records are sent from the principal/primary to the mirror/secondary where the REDO phase is continuously running. When a failover is initiated, only the UNDO phase runs on the mirror/secondary to make it the new principal/primary.
- – Log shipping. This is an automated backup-copy-restore process of transaction log backups. The REDO phase runs when the latest log backup is restored on the secondary and the UNDO phase runs when the databases are recovered.
- – Replication. The Log Reader Agent reads the transaction log records from the Publisher that are marked for replication and converts them to their corresponding DML statements, copied to the Distributor and applied to the Subscribers.
Bottom line is this: availability and recoverability is affected by the amount of transaction log records generated in the database. Now, you might be asking, “how do data types affect HA/DR?”
Suppose you have a table structure similar to the one below. This was actually taken from one of the corrupted databases that I had to recover last week as part of a disaster recovery situation.
CREATE TABLE [dbo].[Users](
[userID] [uniqueidentifier] NOT NULL PRIMARY KEY,
[FirstName] [varchar](255) NULL,
[LastName] [varchar](255) NULL,
[UserLogin] [varchar](255) NULL,
[IsActive] [int] NULL
)
GO
CREATE NONCLUSTERED INDEX NCIX_Users
ON Users (Lastname, Firstname)
INCLUDE (UserLogin,IsActive)
GO
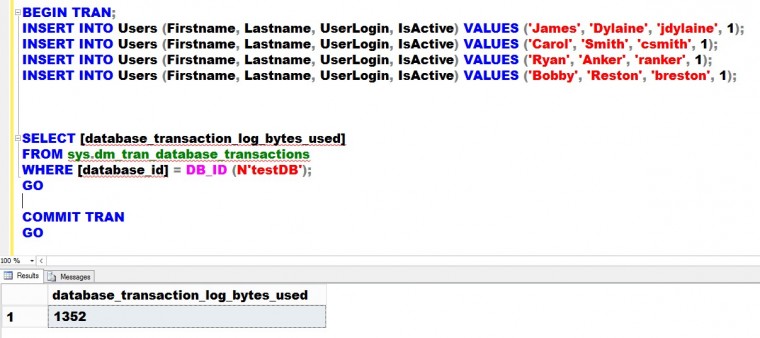
Let’s insert a row in this table and measure how much transaction log record gets generated in the process. Note that I will wrap the INSERT statement in an explicit transaction so I can take a look at the amount of transaction log records using the sys.dm_tran_database_transactions DMV.
BEGIN TRAN;
INSERT INTO Users VALUES (NEWID(), 'James', 'Dylaine', 'jdylaine', 1);
INSERT INTO Users VALUES (NEWID(), 'Carol', 'Smith', 'csmith', 1);
INSERT INTO Users VALUES (NEWID(), 'Ryan', 'Anker', 'ranker', 1);
INSERT INTO Users VALUES (NEWID(), 'Bobby', 'Reston', 'breston', 1);
GO
SELECT [database_transaction_log_bytes_used], [database_transaction_log_bytes_used_system]
FROM sys.dm_tran_database_transactions
WHERE [database_id] = DB_ID (N’testDB’);
GO
COMMIT TRAN
GO
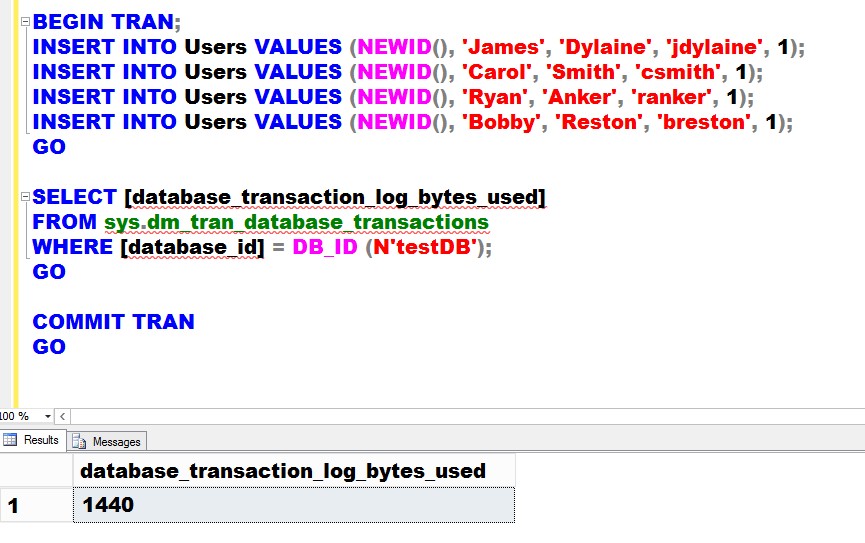
Inserting four (4) records in the table generated 1440 bytes. That’s about 1/8 the size of a data page. Imagine the amount of transaction log records generated if this was a highly transactional table. Now, if you look at the table and index structure, the userID column – a 16-byte column – is assigned as a PRIMARY KEY column. By default, this also becomes the clustered index key. And because the clustered index key is also included in the non-clustered indexes, we are duplicating a 16-byte column for every non-clustered index we create.
What if we make certain modifications on this table based on the column data types? Let’s say that we’ll change the userID column data type from uniqueidentifier to a bigint data type of size 8 bytes and make it an identity column. Note that I am only using this as a simple example as the data types should still meet your business requirements. Let’s also change the IsActive column from an int to a bit data type of size 1 byte since there are only two possible values for this column.
CREATE TABLE [dbo].[Users](
[userID] [bigint] IDENTITY (1,1) NOT NULL PRIMARY KEY,
[FirstName] [varchar](255) NULL,
[LastName] [varchar](255) NULL,
[UserLogin] [varchar](255) NULL,
[IsActive] [bit] NULL DEFAULT 0
)
GO
CREATE NONCLUSTERED INDEX NCIX_Users
ON Users (Lastname, Firstname)
INCLUDE (UserLogin,IsActive)
GO
By doing this, we’ve reduced the row size by 11 bytes. Now, you might be thinking, “11 bytes is almost negligible with today’s disk and memory capacity.” Let’s see. I’ll insert the same four (4) records on the new table structure and measure the amount of transaction log records generated in the process. The corresponding INSERT statements need to be updated as well to reflect the change.
BEGIN TRAN;
INSERT INTO Users (Firstname, Lastname, UserLogin, IsActive) VALUES ('James', 'Dylaine', 'jdylaine', 1);
INSERT INTO Users (Firstname, Lastname, UserLogin, IsActive) VALUES ('Carol', 'Smith', 'csmith', 1);
INSERT INTO Users (Firstname, Lastname, UserLogin, IsActive) VALUES ('Ryan', 'Anker', 'ranker', 1);
INSERT INTO Users (Firstname, Lastname, UserLogin, IsActive) VALUES ('Bobby', 'Reston', 'breston', 1);
GO
SELECT [database_transaction_log_bytes_used]
FROM sys.dm_tran_database_transactions
WHERE [database_id] = DB_ID (N'testDB');
GO
COMMIT TRAN
GO
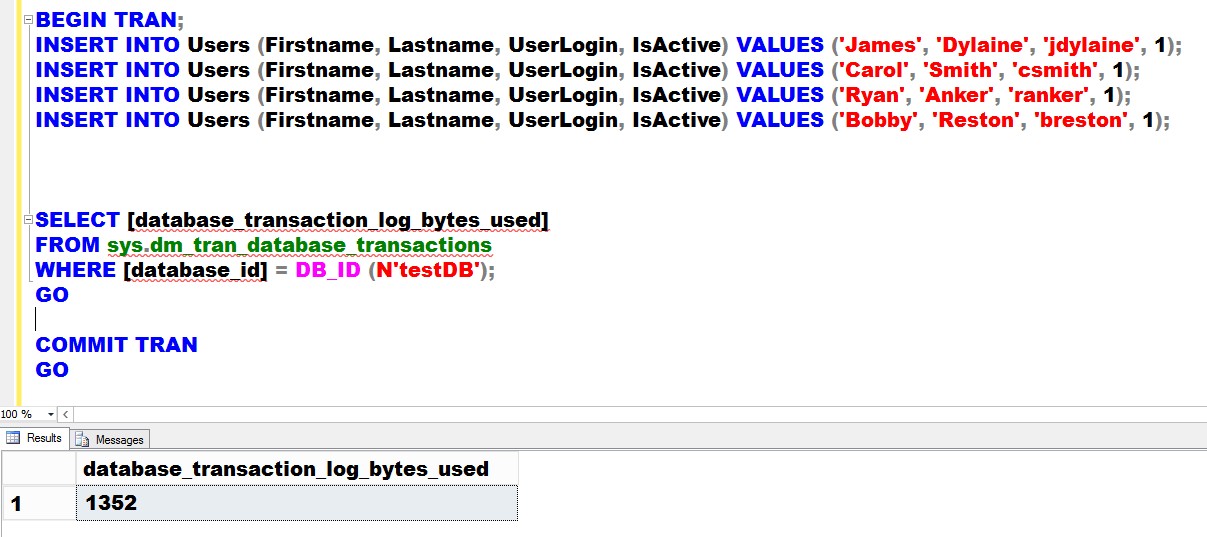
The difference in the amount of transaction log records generated between the two is a mere 88 bytes. You might be wondering, “Didn’t we just reduce the row size by 11 bytes for a total of 44 bytes for all 4 rows? How come we’ve reduced it by 88 bytes?” That’s because the size reduction not just applies to the row itself but to all of the non-clustered indexes since they include the clustered index key. If you do the math, considering a table with 10,000 rows and four (4) non-clustered indexes, you’ve basically reduced the size by 550,000 bytes (550 KB.) And this number just adds up depending on the number of tables, rows and indexes that your database has.
If we want to achieve higher availability by reducing downtime when SQL Server is restarted, failover process initiated or when a database backup is restored, using the smallest yet appropriate sized data type for your columns is just one of many ways to do it. Because we’re reducing the amount of transaction log records generated, the REDO and UNDO phases of the recovery process will definitely run faster (not to mention the amount of log records sent to the mirror/secondary replica will also be reduced.) What I really like about this approach is the fact that doing so also improves your query performance.

Hi Edwin,
Thank you for the post !
I had difficulty in understanding why do people use GUID when it causes performance issues. fragmentation (when generated in random ), increased size of non-clustered index, etc. Some time back we had to put in place index rebuild job with changed fill factor and had to run it at least once during business hours to deal with performance issues caused by high fragmentation.
Recently I got to know Dynamic CRM (DCRM) uses GUID so heavily. If it was so bad, Microsoft could have changed it with some thing else. Appreciate your inputs in understanding what are the situations when GUID has be leveraged.
Thank you for your time. Thank you.
Br,
Anil Kumar
SQL DBA
Hi Anil,
Thanks for the comment. There are a lot of products that use GUID so heavily. There is nothing wrong with GUIDs at all. What’s wrong is how they are used. In most software development teams, you would rarely see someone who has a good understanding of the underlying database platform. Plus, in an environment where release cycles are more concerned about functionality than S.P.A. (security, performance and availability) the developers are forced into making the functionality work as a priority. GUIDs are used as a PRIMARY KEY because they provide uniqueness, especially in a distributed or disconnected-type applications. In distributed or disconnected-type applications, you cannot easily guarantee if a record can be considered unique unless you use something that can at least provide that uniqueness. Hence, why GUIDs are used as PRIMARY KEYS. Unfortunately, by default, PRIMARY KEYS in SQL Server are automatically created as clustered indexes. What is not commonly mentioned is the fact that you can create a PRIMARY KEY that is not necessarily a clustered index. A new column with a much smaller data type can be used as a PRIMARY KEY instead to limit the impacts on S.P.A. (storage, performance and availability.)
Greetings Edwin,
I love your blog. Many thanks for helping all of us to be less bad DBAs.
I’m reading your reply on the GUID case (not a long time ago i read an interesting post of Jeff Moden about them) and i’m wondering….
Did i understand the whole thing bad, or on this sentence “A new column with a much smaller data type can be used as a PRIMARY KEY instead to limit the impacts on S.P.A. (storage, performance and availability.)” you really mean CLUSTERED INDEX KEY instead of PRIMARY KEY?
In my mind (which usually is scattered), and as you said on the blog entry, we get both storage and T-log generation advantages when the CI KEY is small.
At this moment, the only thing i can think about what advantages can a PK (Not Clustered) has for being small (more than, obviously, you know, taking up less space) is related with Foreign Keys.
Thank you again for all you do for the community.
Pablo Dominguez
Pablo,
Yes, I meant PRIMARY KEY, not CLUSTERED INDEX. By default, your PRIMARY KEY gets created as a CLUSTERED INDEX in SQL Server. But you can choose a different CLUSTERED INDEX so your index column is not as wide as a GUID.
Keep in mind, your PRIMARY KEY also gets associated with a FOREIGN KEY. So when you create an index based on the PRIMARY KEY/FOREIGN KEY combination, the GUID column gets replicated across every child table, on every index page created where the GUID column PRIMARY KEY is referenced, etc. So, it’s no longer just a 16-byte column for one table. The difference in size is huge when you count everything else that replies on the PRIMARY KEY