In a previous blog post, I talked about Partition-Level Online Index Operations in SQL Server 2014 and how it affects high availability and disaster recovery. With more features being added in every new version of SQL Server, it’s important to understand how its implementation will affect your overall objectives. One feature that got a lot of attention when it was introduced was In-Memory OLTP.
In-Memory OLTP, in its simplest form, is a memory-optimized database engine integrated within SQL Server designed for OLTP workloads. With the trends in cost reduction for memory and CPU resources, the timing is just right for this feature. I’ve shown this feature in some of the workshops that I’ve done, demonstrating how in-memory OLTP can increase performance of high-volume transactions. You can try it out for yourself by following the workflow of the scripts provided in this MSDN article. And while there are a lot of limitations for in-memory OLTP (it’s the first version, anyway) it’s worth evaluating it as you prepare to migrate your database workloads.
Most of the blog posts and articles that pertain to in-memory OLTP focus on performance improvements. The focus of this blog post is mainly on how logging works with in-memory OLTP.
Let’s start with logging
Every transaction in a SQL Server database gets logged in the transaction log (LDF) file to ensure durability and consistency. SQL Server uses a write-ahead log (WAL) which guarantees that no data modification is written to the data file (MDF/NDF/etc.) before the associated log record is written to the LDF file. The log records associated with a transaction are written to the LDF file regardless of whether or not the transaction committed. When a page is modified (and reflected in the LDF file) but not yet persisted in the MDF/NDF file, it is considered to be a dirty page. During regular checkpoints, committed transactions written on the LDF file are then persisted to the MDF/NDF file. When recovery (or crash recovery) runs, SQL Server reads the LDF file to see if there are committed and/or uncommitted transactions and recovers the database to a state that is consistent to what is written in the LDF file. This is the main reason why I consider the LDF file to be the most important file in a SQL Server database.
But this is for traditional transactions that are executed against traditional tables (I just like calling them that to differentiate them with the newer watchamacallit.) With the introduction of in-memory OLTP, you now have disk-based (traditional) tables and memory-optimized tables. I’m going to refer to them as such since that’s what SQL Server Books Online calls them.
Logging for transactions against memory-optimized tables
When you create an in-memory table and run transactions against it, the transactions do not use write-ahead logging such as when we deal with transactions against disk-based tables. Also, the log records pertaining to transactions against memory-optimized tables are only generated when the transaction commits. Dirty pages are never written to the LDF file. This means that there are fewer transaction log records generated compared to disk-based tables. Fewer transaction log records mean faster log send to Availability Group replicas, fewer log records to roll forward during crash recovery, fewer log records read for replication subscribers, size of your backups, etc. There is more to what really happens during restore and recovery with in-memory OLTP but will save that for future blog posts.
Let’s look at an example code to compare the log records generated between disk-based tables and memory-optimized tables. We’ll create a database that will contain both disk-based and memory-optimized tables.
[callout]CREATE DATABASE testDB[/callout]
GO
--Create a new filegroup for the in-memory optimized objects
ALTER DATABASE testDB ADD FILEGROUP [testDB_mod] CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE testDB ADD FILE (name = [testDB_dir], filename= 'C:\DBFiles\testDB_mod.ndf') TO FILEGROUP testDB_mod;
GO
--Create in-memory table
USE testDB
GO
--table (memory-optimized) to store sales information
CREATE TABLE [dbo].[Sales_InMemory](
[SalesID] [int] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000),
[CustomerID] [int] NOT NULL,
[DateCreated] [datetime2] NOT NULL,
[TotalPrice] [money]
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA);
GO
Let’s populate the memory-optimized table with data. I’m naming the transaction so it will be easier to search for it in the LDF file.
[callout]--populate table with sample data
BEGIN TRAN InMemory
DECLARE @SalesID INT = 0
WHILE @SalesID < 1000
BEGIN
INSERT [dbo].[Sales_InMemory] VALUES (@SalesID,1,GETUTCDATE(),300)
SET @SalesID +=1
END
COMMIT TRAN InMemory
GO [/callout]
We’ll use the undocumented function fn_dblog() to measure the amount of transaction log record generated by the transaction against the memory-optimized table.
WARNING: It is not recommended to use this undocumented fn_dblog() function on your production system. Use at your own risk.
[callout]SELECT SUM([Log Record Length]) totalLogRecordLength FROM fn_dblog(NULL, NULL) [/callout]
WHERE
[transaction id] =
(
SELECT [transaction id] FROM fn_dblog(NULL, NULL)
WHERE [transaction name] = 'InMemory'
)
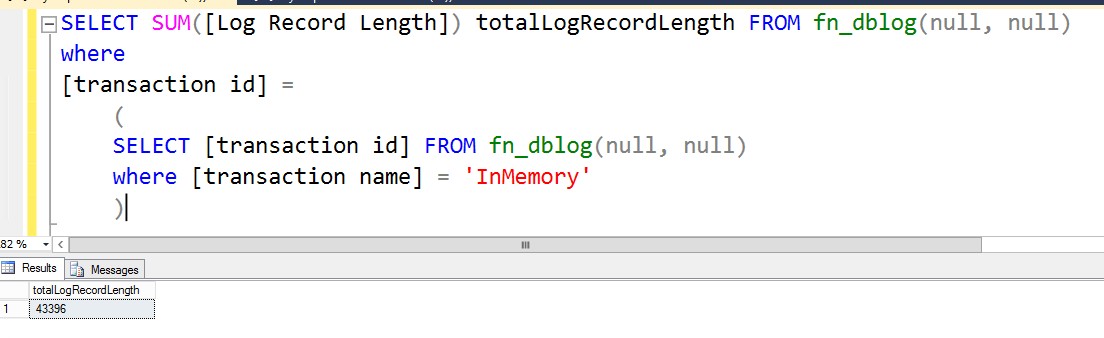 Inserting 1,000 rows in the memory-optimized table generated 43,396 bytes of log records. Let’s do the same thing for a disk-based table.
Inserting 1,000 rows in the memory-optimized table generated 43,396 bytes of log records. Let’s do the same thing for a disk-based table.
[callout]
--Create disk-based table
USE testDB
GO
--table (memory-optimized) to store sales information
CREATE TABLE [dbo].[Sales_Old](
[SalesID] [int] NOT NULL PRIMARY KEY,
[CustomerID] [int] NOT NULL,
[DateCreated] [datetime2] NOT NULL,
[TotalPrice] [money]
)
GO
In the same way, let’s populate the table and use a named transaction to easily search the records in the LDF file.
[callout]--populate table with sample data
BEGIN TRAN DiskBased
DECLARE @SalesID INT = 0
WHILE @SalesID < 1000
BEGIN
INSERT [dbo].[Sales_Old] VALUES (@SalesID,1,GETUTCDATE(),300)
SET @SalesID +=1
END
COMMIT TRAN DiskBased
GO [/callout]
We’ll again use the undocumented function fn_dblog() to measure the amount of transaction log record generated by the transaction against the disk-based table.
[callout]SELECT SUM([Log Record Length]) totalLogRecordLength FROM fn_dblog(NULL, NULL) [/callout]
WHERE
[transaction id] =
(
SELECT [transaction id] FROM fn_dblog(NULL, NULL)
WHERE [transaction name] = 'DiskBased'
)
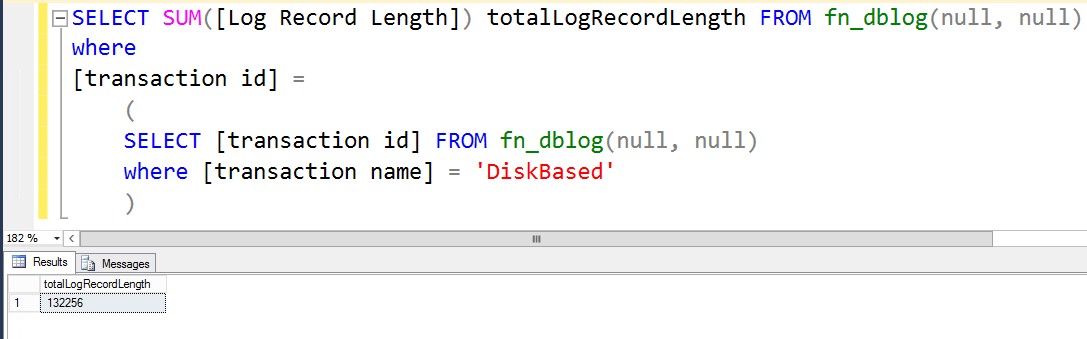
Wow! That’s three (3) times as much log records generated on transactions against disk-based tables versus memory-optimized ones. Which proves that in-memory OLTP transactions provide a much better transaction log throughput compared to the disk-based ones. And that is always a good thing in terms of high availability and disaster recovery.
Caveats
The feature is cool, it’s just not for everyone. Keep in mind that it’s the first iteration. SQL Server MCM Klaus Aschenbrenner (blog | Twitter) wrote an interesting blog post as to why he wouldn’t (yet) recommend it to his customers and I totally agree with him on all his points. There are certain use cases for in-memory OLTP, the most famous one being the solution to ASP.NET session state.
[callout]While some might argue that web session state should not be stored in a relational databases but rather in non-relational stores like Redis cache, the reality is that there are a lot of ASP.NET web applications that use SQL Server for session state management.[/callout]
My biggest pet peeve with this feature is its impact in recovery time objective (RTO,) particularly during database recovery because memory-optimized tables must be loaded into memory before the database is made available. That applies to crash recovery, restoring backups and failover clustered instances. We’ll cover these items in a future blog post.
